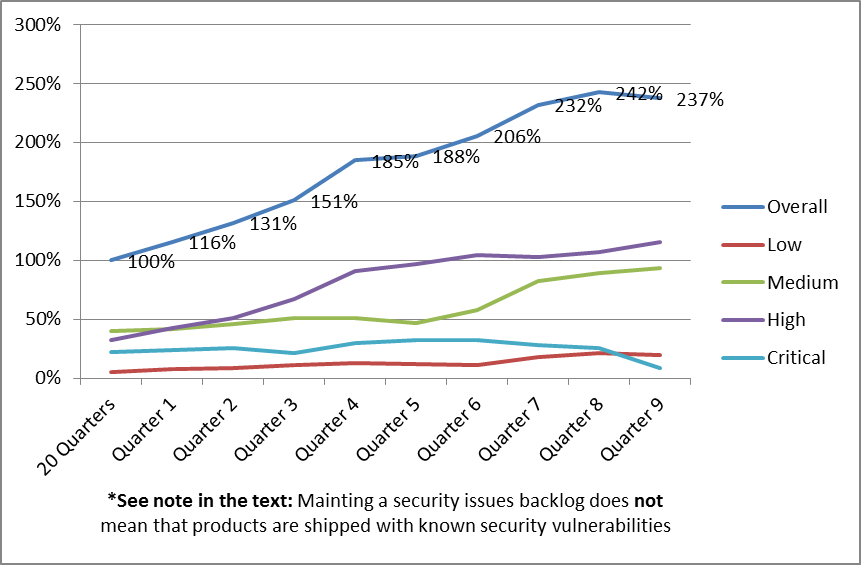
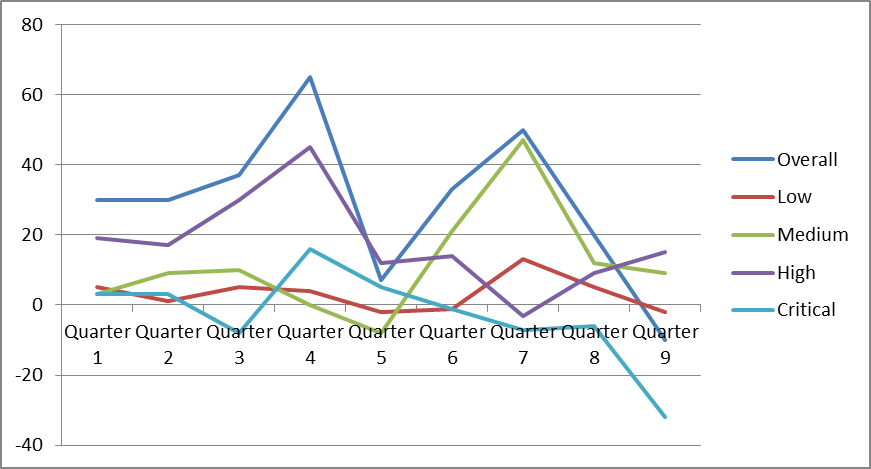
FindBugs is similarly configured for multi-module Maven builds as the Checkstyle and PMD plugins. As in the Checkstyle and PMD example, the configuration example below shows how to set up a “developer build” as the default configuration, allowing a developer to execute FindBugs with the “mvn clean install” command and create data for reports instead of failing the build. As usual, we will use a Maven profile for release builds, so that developers can create local reports, and the CI/CD system can fail the build in case of violations.
The benefits of using a centralized FindBugs filter configuration are in my opinion somewhat limited, but it is still possible to create and use such a configuration artifact (jar resource file) in the Maven FindBugs plugin configuration. The “dependency” section pulls in the configuration artifact, and the “excludeFilterFile” parameter references the FindBugs rules configuration in the resource configuration artifact. This filename must match the actual rules filename used in the dependency. The configuration settings are parameterized with Maven build variables, but this example also works with hardcoded settings.
<build>
...
<plugins>
...
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>findbugs-maven-plugin</artifactId>
<version>${findbugsMavenPluginVersion}</version>
<configuration>
<xmlOutput>true</xmlOutput>
<effort>Max</effort>
<threshold>Low</threshold>
<excludeFilterFile>findbugs-exclude.xml</excludeFilterFile>
<failOnError>false</failOnError>
</configuration>
<dependencies>
<dependency>
<groupId>${buildToolsGroupId}</groupId>
<artifactId>${buildToolsArtifactId}</artifactId>
<version>${buildToolsVersion}</version>
</dependency>
</dependencies>
<executions>
<execution>
<phase>validate</phase>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>
...
</plugins>
...
</build>
The automated continuous integration (CI) build uses the same configuration with the “failOnError” parameter set to “true”:
<profiles>
...
<profile>
<id>release</id>
...
<build>
<plugins>
...
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>findbugs-maven-plugin</artifactId>
<version>${findbugsMavenPluginVersion}</version>
<configuration>
<xmlOutput>true</xmlOutput>
<effort>Max</effort>
<threshold>Low</threshold>
<excludeFilterFile>findbugs-exclude.xml</excludeFilterFile>
<failOnError>true</failOnError>
</configuration>
<dependencies>
<dependency>
<groupId>${buildToolsGroupId}</groupId>
<artifactId>${buildToolsArtifactId}</artifactId>
<version>${buildToolsVersion}</version>
</dependency>
</dependencies>
<executions>
<execution>
<phase>validate</phase>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>
...
</plugins>
...
</build>
...
</profile>
...
</profiles>
Reporting with the “mvn site” command is enabled by including the plugin configuration once more in the POM file’s “reporting” section:
<reporting>
...
<plugins>
...
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>findbugs-maven-plugin</artifactId>
<version>${findbugsMavenPluginVersion}</version>
<configuration>
<xmlOutput>true</xmlOutput>
<effort>Max</effort>
<threshold>Low</threshold>
<excludeFilterFile>findbugs-exclude.xml</excludeFilterFile>
</configuration>
</plugin>
...
</plugins>
...
</reporting>
See https://github.com/mbeiter/util for an example on how to configure the Maven FindBugs Plugin as described in this post for a multi-module build.