
Enabling a CI/CD (Continuous Integration / Continuous Delivery [Deployment]) to create an automated build tool chain commonly requires splitting responsibility and hence control of the build process. A combination of a build management tool like Maven, the Maven Dependency Management plugin, and a reporting engine in a CI tool like Jenkins allows an organization to create a hierarchical control set to specify the behavior of a build.
 As an example, on organization could decide to put organization wide rules in place on how to run secure static code analysis. The organization could empower the CI/CD team to enforce these rules, and also grant exceptions. The CI/CD team could them make these rules available as two Maven POM files: one with the organization wide rules, and one with project specific exceptions to grant the necessary flexibility.
As an example, on organization could decide to put organization wide rules in place on how to run secure static code analysis. The organization could empower the CI/CD team to enforce these rules, and also grant exceptions. The CI/CD team could them make these rules available as two Maven POM files: one with the organization wide rules, and one with project specific exceptions to grant the necessary flexibility.
Projects that inherit their project configuration from the global CI/CD configuration can make further adjustments on a local level, as permitted by the organization’s policy. Maven makes such a setup easily possible through project inheritance, and also allows enforcing usage of the correct ancestors through the Maven Dependency Plugin.
The CI/CD team has a choice of how tightly they want to enforce rules. As an example, they could decide to host the source of the build rules POM files in a dedicated source control repository, or store it with the project sources. They can decide if they want to make these rules a dedicated Maven project, or lump it together with the source code project (I generally recommend making it a separate project to make automated versioning easier).
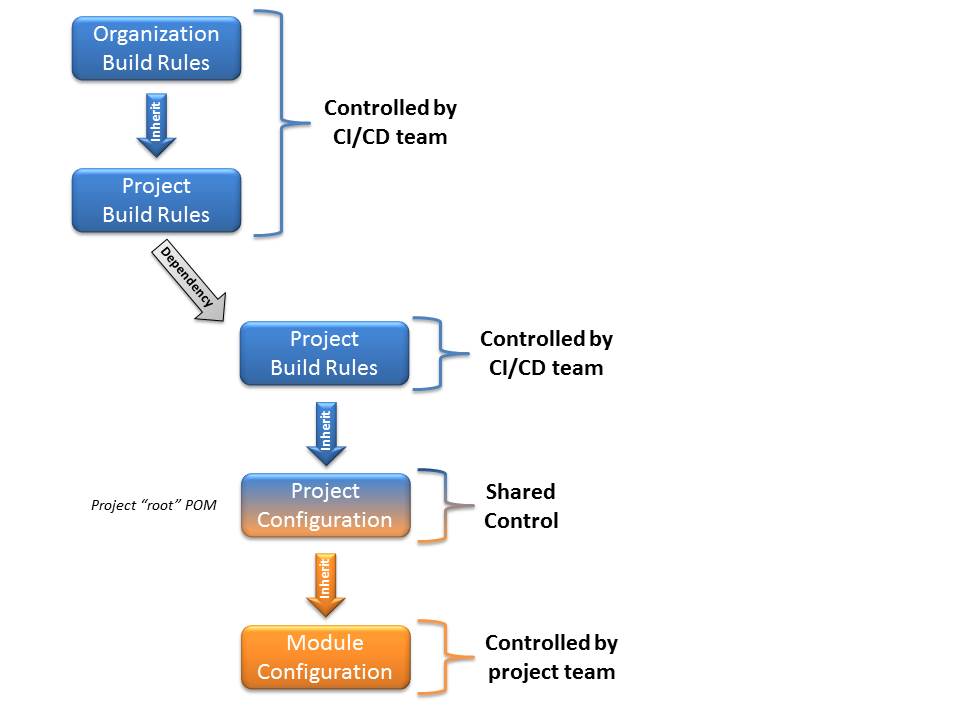
The illustration shows a common enterprise style Maven build setup in a multi-module Maven build, with the blue boxes representing the centrally controlled components of the build configuration (usually represented by at least two different POM files), and the orange box representing the source code modules under the control of the project team. The blue/orange colored box represents the project root POM file, which is commonly where the main project build starts.
I usually recommend having at least three POM files, even for micro projects. The top level POM should contain the general build configuration (at least the license and the SCA rules), the second level POM should contain the project controlled settings, and the third level representing a module in the build with the actual code. This means that every project is a multi-module build, which allows tight control of the build, creates slick reports, and sets the project up for future growth – all with minimal additional effort.
Edit:See https://github.com/mbeiter/util for an example on how to configure a Maven project as a multi-module build with the CI POM separated from the project POM, as discussed in this post. In this example, the majority of the build configuration is combined with the project configuration in the “shared control” root POM. For a bigger project, the build configuration should be pulled out in a separate project, and made available through inheritance, thus reducing the size (and span of control!) of the root POM (as shown in the illustration).